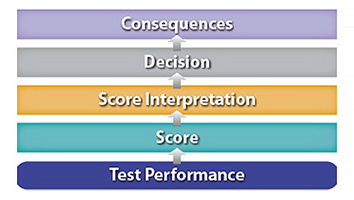
The paper Articulating and Evaluating Validity Arguments for the TOEIC® Tests provides an accessible introduction to the argument-based approach, its implementation for TOEIC tests and its perceived benefits for stakeholders.
The paper begins with a brief overview of the assessment use argument, a prominent argument-based approach to validation. Next, it describes the process used to build validation arguments for TOEIC tests.
This process incorporated evidence from a variety of sources, including test documentation, monitoring activities and research. Finally, the paper provides an overview of the two primary ways in which the TOEIC validation arguments are used: to prioritize research, and to communicate with stakeholders.
Overall, this process demonstrates how TOEIC research takes a broad, critical and rigorous approach to support appropriate uses of the TOEIC tests. This work also intends to improve the assessment literacy of stakeholders by focusing on the critical claims that all test developers should support.